
The Agent Era: A Concise View
Turning language models into reliable, goal-driven software through orchestration, verification, and classic AI principles.

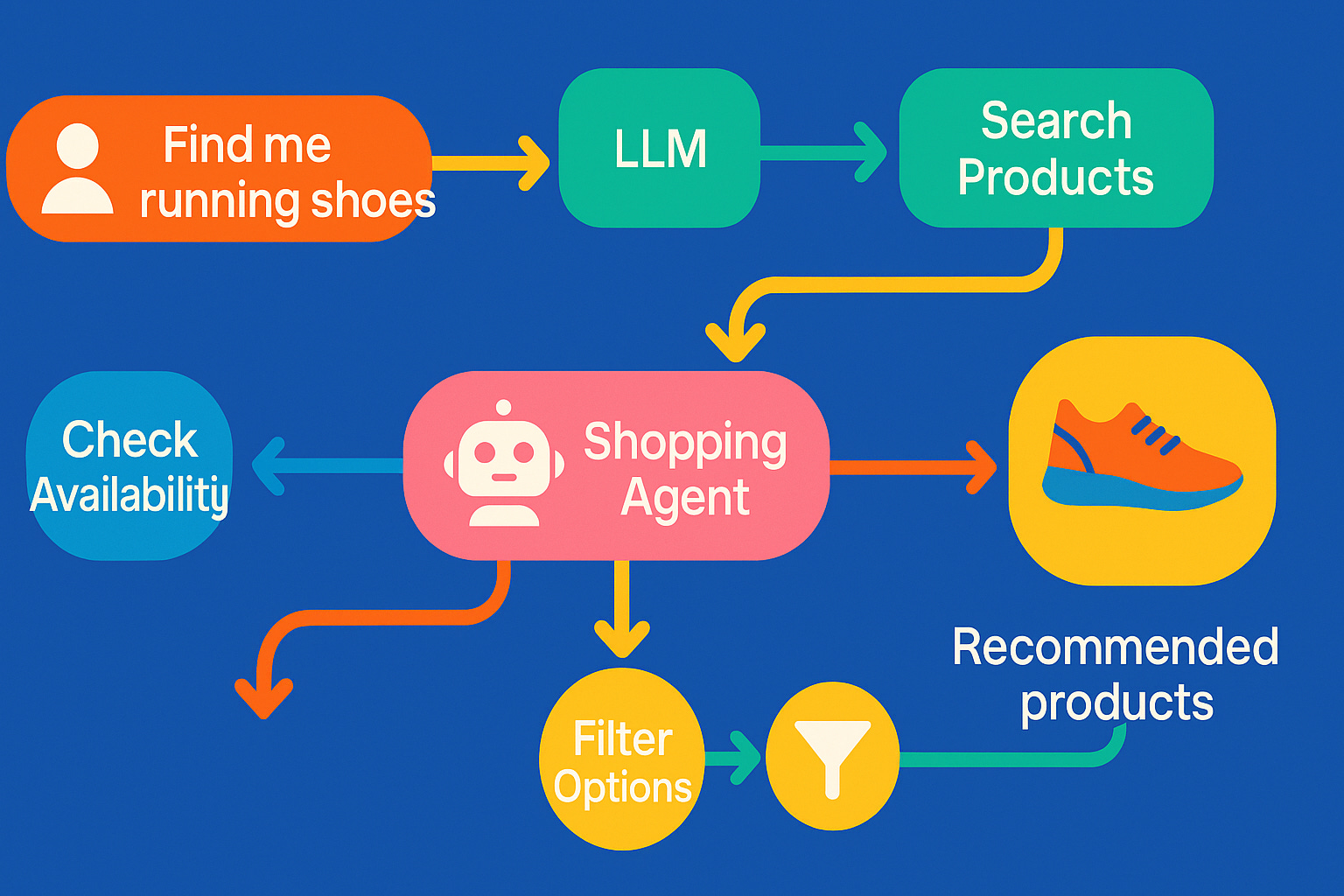
1. Models ≠ Systems
Large language models excel at compressed-knowledge retrieval and fluent token generation, yet they are fundamentally stateless samplers. Lacking an execution stack, scratch-space, or reliable memory, they stumble on branching logic, backtracking, and any multistep task that needs guarantees.
2. Why Orchestration Is Inevitable
Real-world workflows—filing taxes, refactoring code, booking supply chains—demand capabilities an LLM does not ship with:
Planning: break the goal into ordered actions
Tool execution: run code, call APIs, query databases
Validation: confirm intermediate and final results
Persistent state: carry context through retries and failures
These elements must live in an outer control layer that treats the model as a component, not the whole application.
3. Agents as a Programming Framework
A usable agent framework should let practitioners—or power users—declare:
Goals e.g., “Generate a Q3 market brief”
Resources search engine, SQL warehouse, vector index
Policies budget ≤ $0.02, latency ≤ 2 s, PII stays on-prem
Verification hooks unit tests, fact checkers, type schemas
The runtime then decides when to call the model, when to run code, when to fetch external data, and when to roll back or ask for help. In short, an agent is software—it needs observability, versioning, and SLAs just like any other service.
4. Inference-Time Scaling: From Iteration to Coordination
One of the critical dimensions in agent system design is how to scale reasoning at inference time. While foundation models can generate fluent answers in a single forward pass, more reliable outputs typically require either iterative refinement or multi-model coordination.
Single-model scaling uses techniques like:
Chain-of-thought reasoning – inserting intermediate logical steps into the output
Self-refinement – re-prompting the model to critique and revise its own output
Proposal revision – asking the model to generate alternatives and self-rank them
These strategies consume more compute per query, but rely on a single model operating in a longer token window, maximizing likelihood over richer output trajectories.
By contrast, multi-model agentic workflows decouple roles:
A generator proposes candidate solutions
One or more verifiers or reward models evaluate, rank, or reject those candidates
Coordination strategies like majority voting, cross-verification, or branch-and-bound search select the final output
This enables explicit algorithmic reasoning patterns and improves robustness by incorporating diverse model perspectives—but at the cost of higher system complexity and inter-model communication overhead.
Both paradigms trade latency and compute for output quality, but multi-model agent systems more closely resemble traditional planning and inference architectures: they can simulate backtracking, perform structured search, and reduce error through ensemble decision-making. This makes them particularly attractive for high-stakes use cases where reliability, diversity, or correctness matter more than raw speed.
5. State of the Tooling (and the Gaps)
Today’s open-source and vendor stacks already help by:
Hiding boilerplate for API calls
Offering DAG/graph builders for multistep flows
Providing basic retries and error handling
Supporting simple schema validation
But they still lack:
First-class, plug-and-play verifiers to catch hallucinations early
Fine-grained cost and latency budgets
Typed, composable configs that ops teams can statically analyse
Until these gaps close, “agent stacks” will feel like prototypes rather than the next Kubernetes.
6. Classic AI Lineage and the Road Ahead
Long before transformers, AI defined an agent as a loop that perceives, decides, acts, and verifies:
Textbook rational agents (Russell & Norvig, 1995) maximised expected utility.
Robotics pioneers (Rodney Brooks) showed that layered perception-action loops can be surprisingly robust.
Marvin Minsky’s Society of Mind framed intelligence as many specialised processes cooperating through clean interfaces.
The modern “agentic stack” revives those ideas: the decision module is a transformer; perception and action happen via API calls, databases, and code runners rather than sensors and motors. The architectural principle is unchanged—separate planning, action, and verification to achieve reliability.
7. Why Andrew Ng Calls Agentic AI the Most Important Trend
In a recent keynote, Andrew Ng—one of the most influential voices in AI—called agentic workflows the most important trend in the current AI wave. His reasoning is grounded in what we’ve already observed: models alone aren’t enough.
Ng described how most current LLM use is “zero-shot prompting”—a single, linear output from a single prompt. By contrast, an agentic workflow introduces structure:
Write an outline
Search the web if needed
Draft
Critique
Revise
Verify output
Repeat if necessary
These loops of planning, tool use, and revision yield significantly better results. Ng’s teams have seen performance on hard tasks (like coding challenges) jump from 48% to 95% just by using agentic workflows—even without switching to a larger model.
Ng highlights four key agent design patterns:
Reflection – Agents that critique and revise their own output
Tool Use – Models that call external APIs or execute code
Planning – Decomposing complex tasks into sequenced steps
Multi-agent Collaboration – Assigning specialized roles that interact
These aren’t theoretical—Ng’s teams use them in real-world systems for legal, healthcare, and visual AI tasks. His larger point: model development has accelerated, but evaluation, orchestration, deployment, and reliability have not. Agents fill that gap—transforming prototypes into products.
Ng also points to a new layer in the AI stack emerging: the agentic orchestration layer, where frameworks like LangGraph, AutoGen, and Landing AI’s vision agents live. They are essential to move from fluent responses to trustworthy systems.
8. Rethinking Evaluation: From Model Scores to System Trust
Despite rapid progress in large language models, agent evaluation today remains overly model-centric. Benchmarking a model’s performance on isolated tasks—summarization, coding, retrieval—does little to capture how well an agent performs in the real world.
What matters in practice is whether the entire agentic system reliably delivers results in messy, dynamic environments. That means we need to evaluate not just what the model knows, but how well the system behaves:
Task Success – Does the agent consistently achieve end-to-end goals under real-world conditions?
Correct Tool Use – Does it choose the right APIs, trigger them with valid inputs, and handle outputs correctly?
Robustness – How well does it handle ambiguous instructions, tool failures, or mid-task changes?
Efficiency – Does it minimize unnecessary steps, retries, and latency?
Memory & Context – Can it track information across multiple turns or nested flows?
Generalization – Can it adapt its behavior to new tasks or variations it wasn’t explicitly trained for?
User Experience – Is the interaction intuitive, responsive, and reliable for a non-technical user?
Safety & Ethics – Does it avoid triggering unsafe actions or violating constraints?
Agentic AI raises the bar: benchmarks should test systems, not just token-level outputs. Progress in evaluation will come from designing longitudinal, failure-aware, and user-grounded tests—mirroring what real practitioners face in production.
Until then, “agent evaluation” risks measuring the wrong thing: model cleverness in isolation rather than system competence under pressure.
3. Bottom line
The moment you ask an LLM to do more than chat, you need a surrounding control layer that plans, acts, and verifies. That’s the architectural leap—from stateless generation to agentic orchestration—that transforms potential into reliability.
We are entering a phase shift:
Model scale is no longer the differentiator; orchestration quality is.
Evaluation is moving from token-matching to system-level trust.
Tool use, verification, and planning are becoming table stakes, not research novelties.
And the fastest-moving teams will treat agents as structured software, not speculative prompts.
In the next 12–18 months:
Expect agent frameworks to consolidate, with clearer abstractions for planning, memory, and verification.
Enterprise adoption will hinge on cost-governed, verifier-backed, and observable agents.
Fast iteration will dominate prototyping—but only teams who solve testing and reliability will succeed in production.
Agents will stop being "assistants" and start becoming active participants in infrastructure, data processing, and decision-making.
The agent era isn’t just coming—it’s already routing around static LLM pipelines. What matters now is who builds systems that can think, act, adapt—and be trusted.